لمحة عن وحدات معالجة الرسومات (GPU) ووحدات المعالجة المسرعة (APU) القائمة على بنية رسومات RDNA 3، وشرائح الجسر النشط لبراءات الاختراع AMD مع ذاكرة تخزين مؤقت مدمجة لتصميمات متعددة الشرائح

نشرت AMD براءة اختراع جديدة تتحدث فيها الشركة عن رقاقة نشطة تعمل كجسر بين العديد من قوالب GPU، ربما بناءً على بنية RDNA 3 من الجيل التالي لوحدات معالجة الرسومات ووحدات APU.
قد تعطينا براءة اختراع AMD Active Bridge Chiplet لمحة عن وحدات معالجة الرسومات (GPU) ووحدات المعالجة المسرعة (APU) من الجيل التالي من RDNA 3
تبدأ فكرة براءة الاختراع من خلال فيل في غرفة وهذا هو تصميمات وحدة معالجة الرسومات التقليدية المتجانسة. نعلم جميعًا مدى جودة عمل chiplets لـ AMD في قطاع وحدة المعالجة المركزية وتخطط الشركة الآن لاتباع نفس المسار على جانب وحدة معالجة الرسومات. ليس من المستغرب أن تستثمر NVIDIA، منافس AMD، أيضًا في تصميمات MCM التي سيتم استخدامها في الجيل التالي من وحدات معالجة الرسومات. من المنطقي أيضًا أنه اعتبارًا من الآن، يعد تقدم تقنية العملية عاملاً حاسمًا ولا يمكنك تقليل حجم وحدات معالجة الرسومات بقدر ما كان في الأيام الخوالي بالنظر إلى مدى اختلاف IPs التي تحزمها وحدة معالجة الرسومات الفردية هذه الأيام.
يتمثل حل AMD في الاستثمار في تصميمات chiplet للجيل التالي من معماريات وحدة معالجة الرسومات. يمكننا القول أن هذه هي أول نظرة لنا على بنية RDNA 3 أو البديل المستقبلي لـ RDNA.
تذكر AMD أنها تواجه مشكلة في جعل العديد من وحدات معالجة الرسومات تعمل بالتوازي، فكر في Crossfire وهي تقنية زائدة عن الحاجة كما هو الحال مع جميع تطبيقات GPU المتعددة.
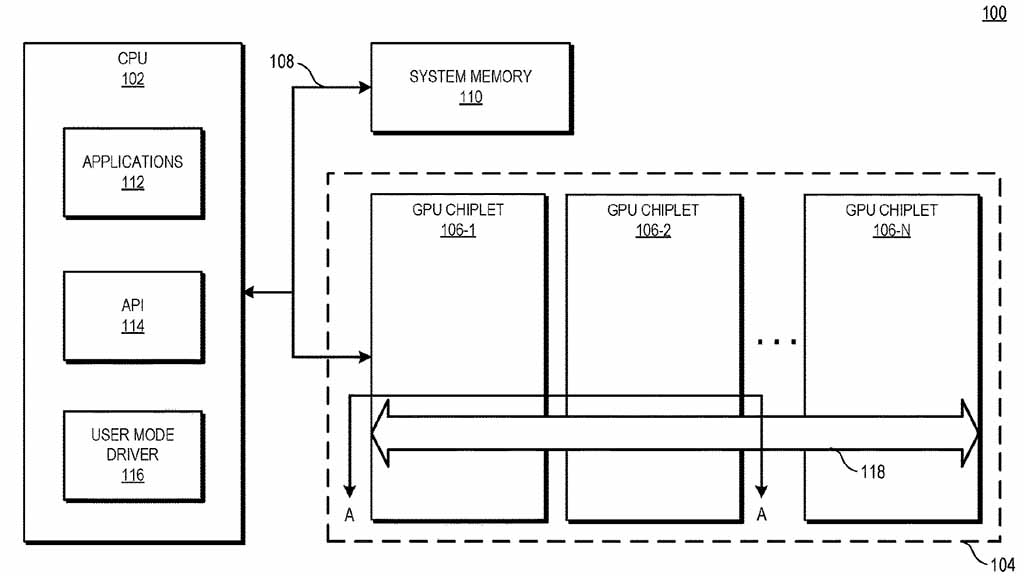
لإصلاح هذه المشكلة وجعل نموذج البرمجة يعمل مع chiplet، اقترحت AMD شريحة جسر نشطة من شأنها أن تربط عدة شرائح GPU معًا.
يُظهر مخطط الكتلة الرئيسي للتصميم المفاهيمي شريحة تحتوي على شرائح متعددة. يتم توصيل جزء وحدة المعالجة المركزية بأول شريحة GPU عبر ناقل اتصال (الجيل المستقبلي من Infinity Fabric) بينما يتم توصيل شرائح GPU عبر شريحة الجسر النشط. هذه واجهة ناقل أثناء التشغيل تصل عدد n-number من وحدات chiplets لوحدة معالجة الرسومات. الأمر الأكثر إثارة للاهتمام هو أن الجسر سيحتوي أيضًا على L3 LLC (Last Level Cache) وهو متماسك وموحد عبر مجموعات متعددة، مما يقلل من اختناقات ذاكرة التخزين المؤقت. وبالتالي يسمح AMD Active Bridge Chiplet بالعمل المتوازي للشرائح على نماذج البرمجة الحالية ويقلل من الحاجة إلى وجود مخابئ L3 منفصلة لكل شريحة GPU.
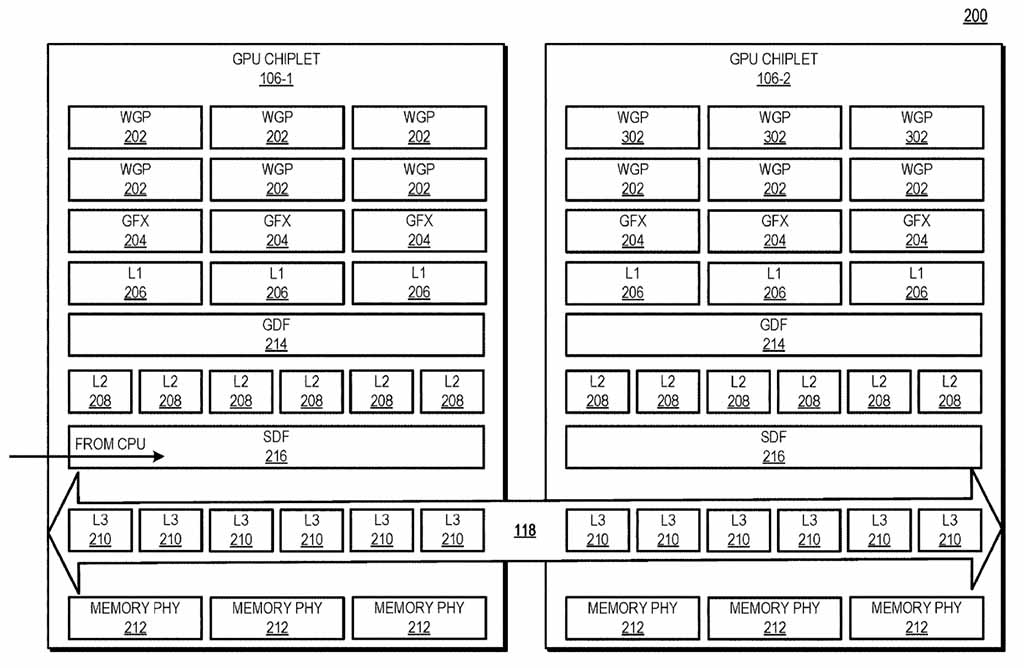
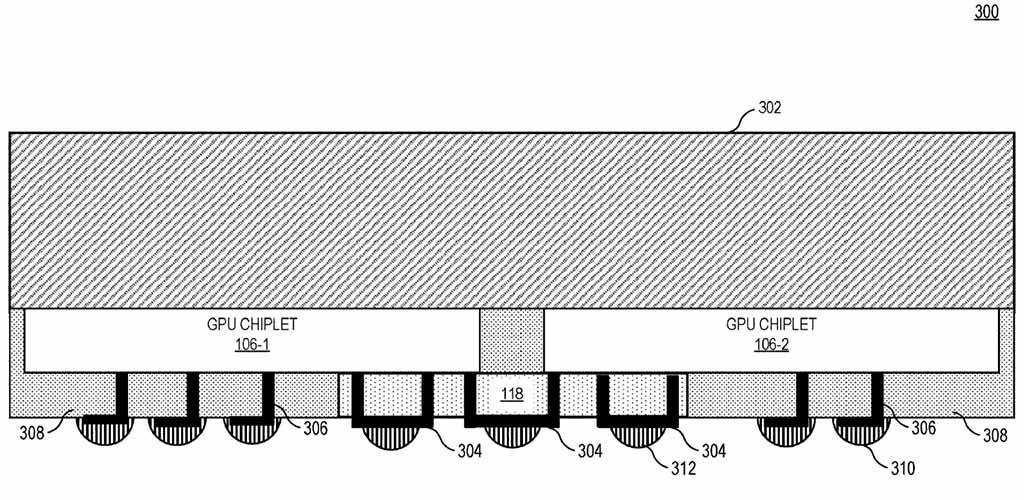
يرمز الشكل 2 عن رسم تخطيطي للكتل يوضح طريقة عرض مقطعية لشرائح وحدة معالجة الرسومات والوصلات المتقاطعة الخاملة وفقًا لبعض النماذج.
يرمز الشكل 3 عن رسم تخطيطي للكتل يوضح تسلسل هرمي لذاكرة التخزين المؤقت لشرائح وحدة معالجة الرسومات (GPU) مقترنًا بوصلة تشابكية سلبية وفقًا لبعض النماذج.
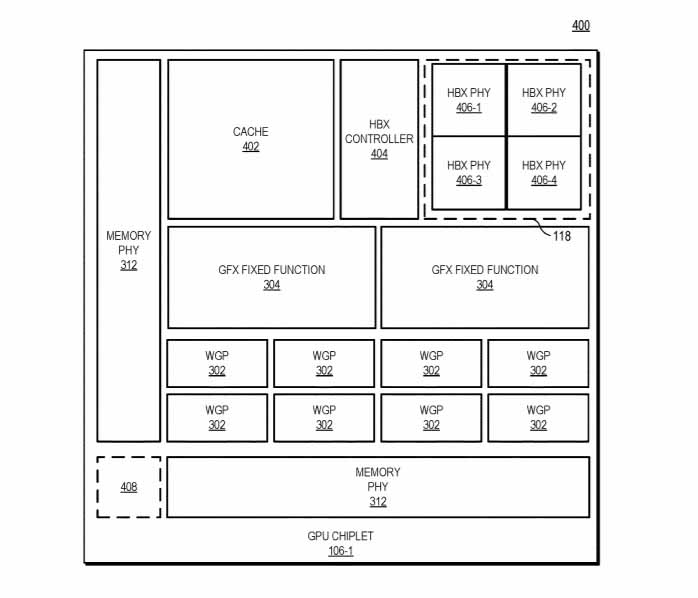
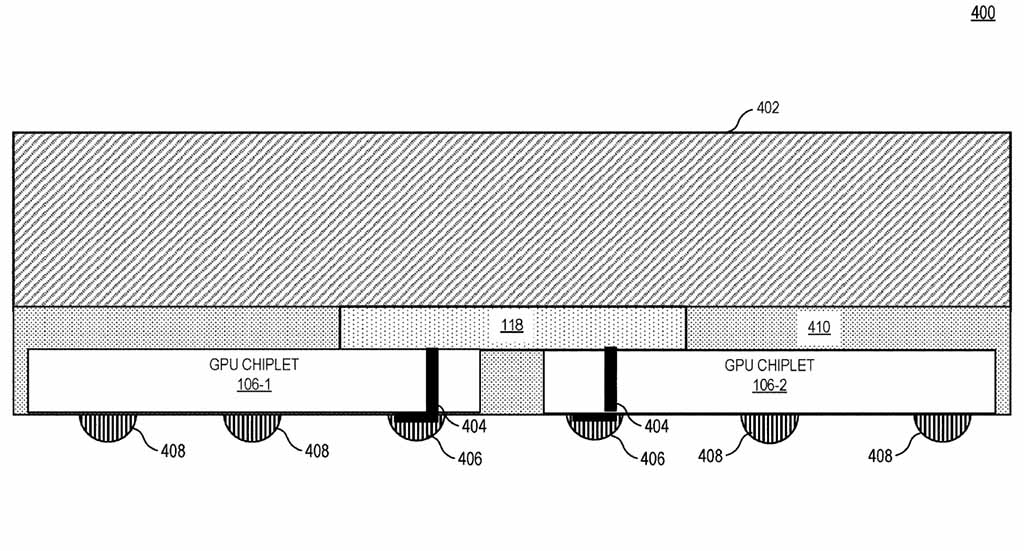
يرمز الشكل 4 عن مخطط كتلة يوضح عرض مخطط الأرضية لشريحة وحدة معالجة الرسومات وفقًا لبعض النماذج.
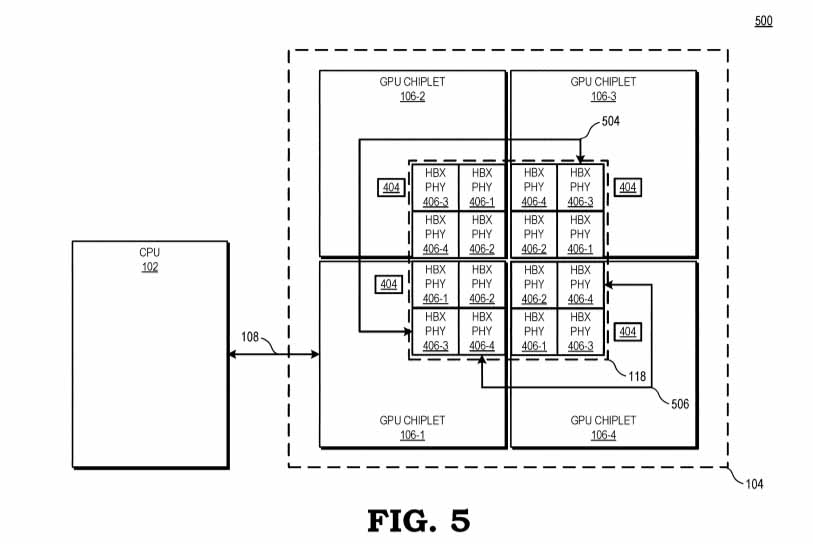
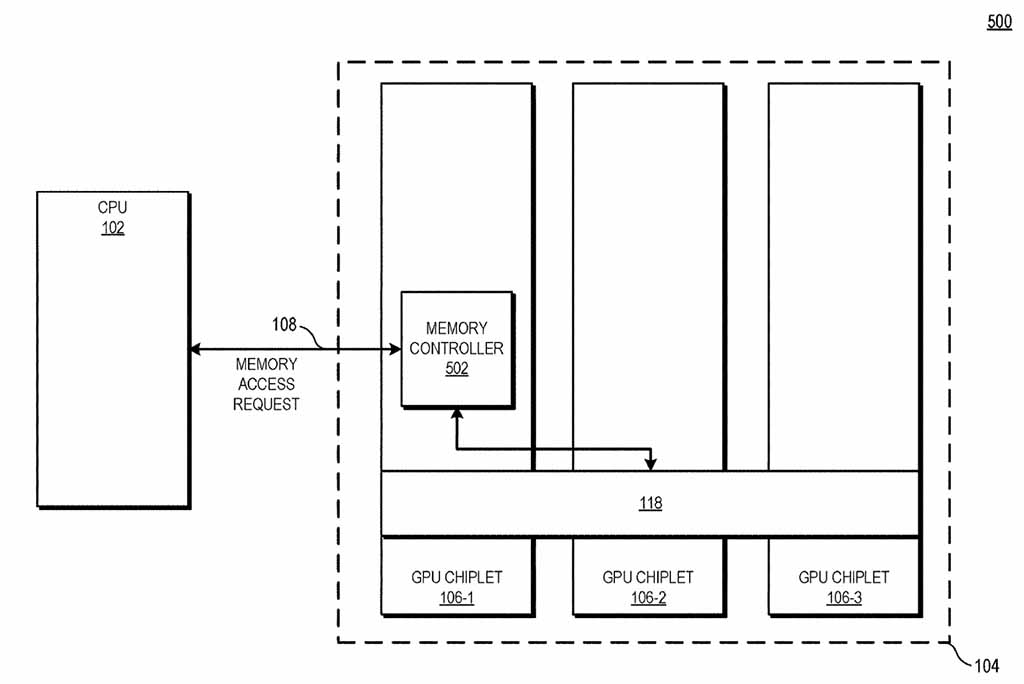
يرمز الشكل 5 عن مخطط كتلة يوضح نظام معالجة يستخدم تكوينًا من أربع شرائح وفقًا لبعض النماذج.
حاليًا، يتحدث مخطط الكتلة عن تصميم SOC الذي يلمح إلى أن هذا قد يكون تصميمًا لوحدات APU المستقبلية القائمة على AMD RDNA 3 للتنقل ومنصات الكمبيوتر المكتبي ووحدات التحكم، ومع ذلك، يجب أن نتوقع أيضًا تنفيذًا مشابهًا على وحدات معالجة الرسومات المنفصلة لرسومات بطاقات الكمبيوتر المكتبي ومنتجات HPC المستقبلية بناءً على معماريات CDNA 2 و CDNA 3.
سيكون من المثير للاهتمام رؤية هذا العمل التقني على AMD Radeon و Instinct GPU في المستقبل.

حاليًا، تتميز AMD بحلول Infinity Fabric و Infinity Cache على خط RDNA 2 الحالي من رقائق الرسومات، لذا يمكن للمرء أن يتوقع مخطط تسمية مثل Infinity Bridge لهذا الحل بمجرد إطلاقه.




