

تم اختبار أداء زمن انتقال الذاكرة لبنية AMD’s RDNA 2 و NVIDIA’s Ampere GPU بواسطة Chips and Cheese . قرر المنفذ التكنولوجي اختبار أداء زمن انتقال ذاكرة وحدة معالجة الرسومات لأحدث معمارية وحدة معالجة الرسومات من فريق اللون الأحمر وفريق اللون الأخضر واكتشف بعض النتائج المثيرة للاهتمام.
تتميز وحدات معالجة الرسومات RDNA 2 من AMD بأداء فائق في زمن انتقال الذاكرة مقارنةً بمعمارية NVIDIA’s Ampere GPU
على جانب وحدة المعالجة المركزية CPU، أصبح قياس أداء ذاكرة التخزين المؤقت ووقت الاستجابة مؤشرًا حاسمًا مع الاستخدام المتزايد باستمرار لقوالب متعددة الشرائح والعديد من شرائح الإدخال والإخراج على متن نفس القالب وفي الحالات الأخيرة ، تم إيقاف التشغيل أيضًا (AMD Zen chiplets).
تتكون وحدات معالجة الرسومات GPU أيضًا على العديد من التسلسلات الهرمية لذاكرة التخزين المؤقت التي تملأ الفجوات بين أداء الحوسبة والذاكرة والمصدر الذي يستخدم مؤشر OpenCL القائم على مطاردة المعايير لقياس ذاكرة التخزين المؤقت وأداء زمن انتقال الذاكرة على الجيل الحالي من وحدات معالجة الرسومات مثل معمارية NVIDIA Ampere و AMD RDNA 2.
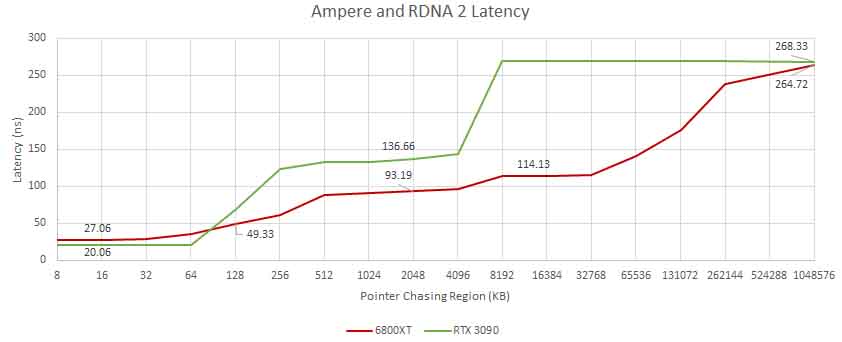
في اختبار المعايير benchmarks، تم وضع AMD Radeon RX 6800 XT (RDNA 2 GPU) و NVIDIA GeForce RTX 3090 (Ampere GPU) ضد بعضهما البعض.
يُظهر اختبار معيار cache و memory أن بنية AMD RDNA 2 كانت أفضل بكثير من وحدة معالجة الرسومات Ampere، مما يوفر وقت استجابة أقل، على الرغم من الحاجة إلى التحقق من مستويين آخرين من cache و وصولاً الى memory.
يضيف استخدام ذاكرة التخزين المؤقت اللانهائية 20 نانوثانية فقط على ضرب L2 ولا يزال أسرع من Ampere.
السبب المذكور هو أن وحدة معالجة الرسومات GA102 المستندة إلى معمارية Ampere هي ببساطة وحدة معالجة رسومات أكبر بكثير ، وبينما تستخدم نظامًا فرعيًا لذاكرة GPU أكثر تقليدية مع مستويين فقط من ذاكرة التخزين المؤقت ، يجب أن تستغرق الكثير من الدورات وتؤدي إلى زمن انتقال يزيد عن 100 ثانية (L1 إلى L2). بينما RDNA 2 لديه زمن انتقال يبلغ 66 ثانية فقط.
لاحظ أن وحدة معالجة الرسومات AMD Navi 21 أصغر بكثير وتتميز بذاكرة تخزين مؤقت سعة 4 ميجابايت بينما تتميز وحدة معالجة الرسومات NVIDIA GA102 بذاكرة تخزين مؤقت L2 سعة 6 ميجابايت للشريحة بأكملها.
تتميز وحدة معالجة الرسومات NVIDIA A100 Ampere الخاصة بـ HPC بذاكرة تخزين مؤقت ضخمة سعة 40 ميجابايت.

فيما يلي ملاحظة حول الأداء من Chips and Cheese:
ذاكرة التخزين المؤقت لـ RDNA 2 سريعة وهناك الكثير منها. بالمقارنة مع Ampere ، يكون زمن الانتقال منخفضًا على جميع المستويات. تضيف Infinity Cache حوالي 20 نانوثانية فقط على نتيجة L2 ولديها زمن انتقال أقل من Ampere’s L2. من المثير للدهشة أن زمن انتقال VRAM الخاص بـ RDNA 2 هو نفسه تقريبًا مثل Ampere ، على الرغم من أن RDNA 2 يقوم بفحص مستويين آخرين من ذاكرة التخزين المؤقت في الطريق إلى الذاكرة.
في المقابل ، تلتزم Nvidia بنظام فرعي لذاكرة GPU أكثر تقليدية مع مستويين فقط من ذاكرة التخزين المؤقت وزمن وصول L2 مرتفع. يستغرق الانتقال من L1 الخاص بـ Ampere إلى L2 أكثر من 100 نانوثانية. يقع L2 الخاص بـ RDNA على بعد 66 نانوثانية تقريبًا من L0 ، حتى مع وجود ذاكرة تخزين مؤقت L1 بينهما. يبدو أن حل مشكلة الموت الهائل لـ GA102 يستغرق الكثير من الدورات.
قد يفسر هذا الأداء الممتاز لـ AMD بدقة أقل. قد تمنح مخابئ RDNA 2 ذات زمن الوصول المنخفض L2 و L3 ميزة مع أحمال عمل أصغر ، حيث يكون الإشغال منخفضًا جدًا لإخفاء زمن الانتقال. تتطلب رقائق Nvidia’s Ampere مزيدًا من التوازي للتألق.
بواسطة Chips and Cheese
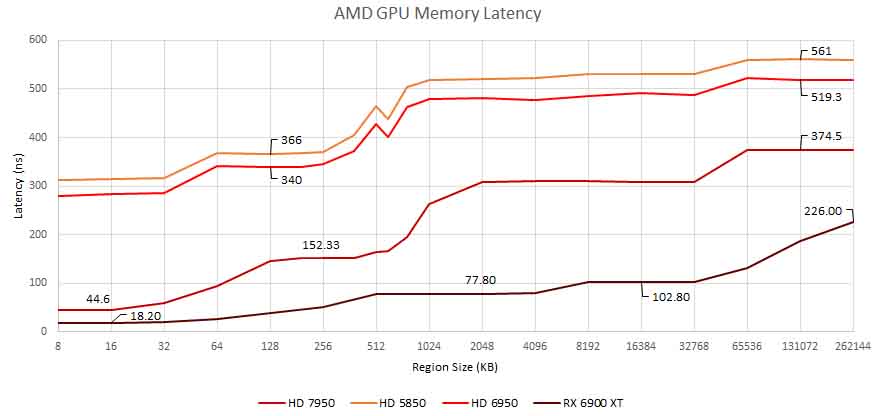
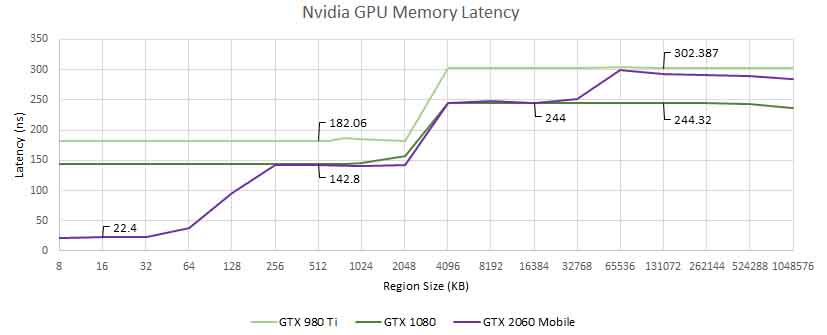
مقارنةً بشرائح Pascal و Maxwell الأقدم ، أدت بنية Ampere إلى تحسين سرعات زمن الانتقال على وحدات معالجة الرسومات الأكبر كثيرًا. من ناحية أخرى ، أظهرت AMD بعض المكاسب المثيرة للإعجاب مقابل رقائق GCN و VLIW القديمة القائمة على معمارية. من المؤكد أن هذه الأرقام ستكون مثيرة للاهتمام للمقارنة بمجرد أن تصل الجولة الجديدة من وحدات معالجة الرسومات التي تعتمد على رقاقة إلى قطاع الألعاب في السنوات القادمة.


